HTTP 请求的基础知识
超文本传输协议 HTTP 的设计目的是保证客户机与服务器之间的通信。HTTP 的工作方式是客户机与服务器之间的请求-应答协议。Web 浏览器可能是客户端,计算机上的网络应用程序也可能作为服务器端。例如:客户端(浏览器)向服务器提交 HTTP 请求;服务器向客户端返回响应。响应包含关于请求的状态信息以及可能被请求的内容
HTTP 是基于 TCP/IP 通信协议来传递数据(HTML 文件,图片文件,查询结果等)
HTTP 是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议
HTTP 工作原理
HTTP 协议工作于客户端-服务端架构上。浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求
Web 服务器有:Apache 服务器、IIS 服务器(Internet Information Services)等
Web 服务器根据接收到的请求后,向客户端发送相应信息
HTTP 默认端口号为 80,但是也可以改为 8080 或其他端口
⚠️注意事项
- HTTP 是无连接的: 无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户端的应答后,即断开连接。采用这种方式可以节省传输时间
- HTTP 是媒体独立的: 这意味着,只要客户端和服务器知道如何处理数据的内容,任何类型的数据都可以通过 HTTP 发送。客户端以及服务器指定使用适合的 MIME-type 内容类型即可
参考链接: MIME types
结构:type/subtype;parameter=value
例如:text/json、text/html、text/javascript、image/png
- HTTP 是无状态的: HTTP 协议是无状态协议。无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。缺少状态意味着打开一个服务器上的网页和上一次打开这个服务器上的网页没有任何关系,也即如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大;另一方面,在服务器不需要先前信息时它的应答就较快
HTTP 协议通信流程: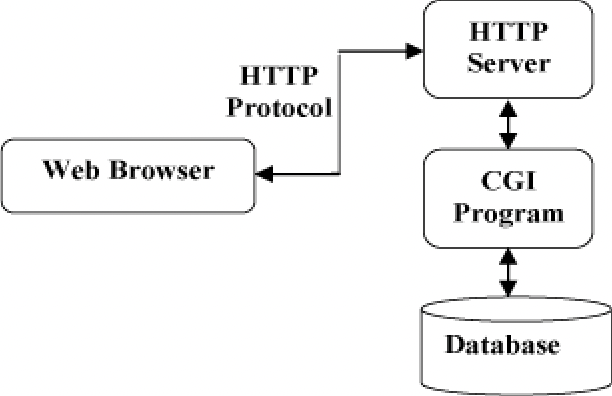
HTTP 请求方法
根据 HTTP 标准,HTTP 请求可以使用多种请求方法
HTTP1.0 定义了三种请求方法:GET、POST、HEAD
HTTP1.1 定义了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE、CONNECT
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)数据被包含在请求体中 (Request Body)。POST请求可能会导致 新资源的建立 和/或 已有资源的修改(可用于数据的新增/更新) |
| 3 | PUT | 从客户端向服务器传送的数据将被用于取代指定的文档的内容(用于对数据的全覆盖更新) |
| 4 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新(用于对数据的局部更新) |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于仅获取报头 |
| 7 | CONNECT | HTTP/1.1 协议中预留的能够见链接改为管道方式的代理服务器 |
| 8 | OPTIONS | 允许客户端查看服务器的性能 |
| 9 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
URI 与 URL 的区别
- URI: Universal Resource Identifier 统一资源标识符
URL: Universal Resource Locator 统一资源定位符 - URI 用于标识,是在某一规则(协议,如 HTTP)下针对一个网络资源的唯一标识,作用如同 primary key
URL 用于定位,因此也是一种 URI;而 URI 并不一定可以作为 URL
例如我们并无法通过唯一的身份证号定位到一个人所处的位置,但是地址可以
In computing, a URL is a subset of the URI that specifies where an identified resource is available and the mechanism for retrieving it. In popular usage and in many technical document and verbal discussion it is often incorrectly used as a synonym for URI. 计算机领域中,URL 是一种特殊的指明了资源位置和获取规则的 URI;但要注意的是我们可能会看到在很多文章中并不会按照 URI 和 URL 的定义对他们严格的加以区分动物住址协议://地球/中国/广东省/深圳市/南山区/粤海街道/222号/302室/张三.人
GET 与 POST 的区别
在客户端和服务器之间进行 请求-响应 时,两种最常被用到的方法是 GET 和 POST
- GET 提交的数据会放在 URL 之后,以 ? 分隔 URL 和传输数据,参数之间以 & 相连
– 如果数据时英文字母或数字,原样发送
– 如果是空格,转换为 +
– 如果是中文或其他自符,则直接把字符串用 BASE64 加密
POST 请求是把提交的数据放在 HTTP 包的 Body 中 - GET 提交的数据 有长度限制(因为浏览器对 URL 的长度有限制)
POST 方法则对数据没有长度要求 - GET 方式提交数据的信息对所有人都是可见的,会带来安全问题,比如一个登录页面,通过 GET 方式提交数据时,用户名和密码将出现在 URL 上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从浏览器的历史记录中获得该用户的账号和密码
- GET 请求可以被缓存;POST 请求不会被缓存
- GET 请求会被保留在浏览器历史记录中;而 POST 请求不会
- GET 请求可以被收藏为书签;而 POST 请求不会
/test/demo.html?username=name&password=pwd
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
POST 与 PUT 的区别
- POST 方法用于创建一个资源;PUT 方法用于更新或创建一个资源
- 英文解释或许更清晰:
– PUT implies putting a resource - completely replacing whatever is available at the given URL with requested thing
PUT 用于对指定的 URL 对应资源进行完全覆盖的新增或更新操作
– POST updates a resource, adds a subsidiary resource, or causes a change
POST 用于对指定 URL 的资源池创建一个子资源 - PUT 方法具有幂等性,无论向同一 URL 执行多少次相同的 PUT 操作,都将产生一样的效果,如同 “ x = 5 “,不断替换指定 URL 的内容
POST 方法不具有幂等性,多次执行的效果会累加,如同 “ x++ ”,不断向指定 URL 新增子资源
幂等元素是指被自己重复运算(或对于函数是为复合)的结果等于它自己的元素 - PUT creates THE new resource with newResourceId as the identifier, under the /resources URI, or collection
POST creates A new resource under the /resource URI, or collection. Ususally the identifier is returned by the server
当创建一个资源时,不可使用其相关信息 (id/name/..) 作为 POST 该资源的 URL,但是可以向该 URL 做 PUT 操作。例如以下操作只可使用 PUT 方法,因为 new_question 资源还不存在,POST 方法会报出“资源不存在”的错误
若要使用 POST 请求创建资源,应当如下操作。但是要注意的是,如此操作并未由请求发送方指定新建资源的 URL,而是在创建成功后由服务器返回新资源位置,当然 PUT 方法也可以如此操作PUT /resources/<newReourceId> HTTP/1.1 Host: www.example.com/
总结来说,POST /resources HTTP/1.1 Host: www.example.com/
– PUT is for creating when you know the URL of the thing you will create
– POST is for creating when you know the factory or the manager of the cateory of things you want to create
PUT 用于当希望且能够自行指定新建资源的 URL 时;POST 用于当仅知道新建资源池的 URL 时POST /report return id = 1001 PUT /report/1001 - 当更新一个资源时,
POST /questions/<existing_question> HTTP/1.1 Host: www.example.com/ PUT /questions/<existing_question> HTTP/1.1 Host: www.example.com/
举个栗子
下述两个 URI 可以同时使用,其中的 john 在两个地址中分别表示不同的含义(资源/资源池)
Note that a resource can contain a collection
下述栗子中的 john 表示资源 john 本身,可能用于展示用户 john 的某些信息
URI: website.com/users/john
website.com - whole site
users - collection of users
john - items of the john collection, or a resource with identifier 'john'
下述例子中的 john 表示资源池 john 所拥有的所有资源,甚至可能是另一资源池,比如 posts/tweets/books 等等
URI: website.com/users/john/posts/23
website.com - whole site
users - collection of users
john - items of the collection john, or a resource with identifier 'john'
posts - collection of posts from john
23 - post with identifier 23 from john, also a resource
注意事项
虽然并没有实际对 URI 的含义和请求方法做特殊限定,但应当注意 POST 请求只应被用于向某资源池 URI 内新加一个该类资源
下面的例子虽然也能正常请求,但其表达的含义应当是向 john 的资源池内新增某个资源
POST /users/john HTTP/1.1
而当使用 PUT 方法时,则是针对特定的资源进行的更新操作,或者该 URI 指向的资源如果不存在的话就新增
PUT /users/john HTTP/1.1
HTTP 状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在的服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码 (HTTP Status Code) 的信息头 (server header) 用以响应浏览器的请求
以下是常见的 HTTP 状态码:
200 - 请求成功
301 - 资源 (网页等) 被永久转移到其他 URL
404 - 请求的资源 (网页等) 不存在
500 - 内部服务器错误
HHTP 状态码分类
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。共分为 5 种类型
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | (请求成功)表示成功处理了请求的状态代码 |
| 3** | (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向 |
| 4** | (客户端错误)请求包含语法错误或无法完成请求 |
| 5** | (服务器错误)服务器在处理请求的过程中发生了错误 |
常见状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议,智能切换到更高级的协议。例如,切换到 HTTP 的更新版本协议 |
| 200 | OK | (请求成功)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。一般用于 GET 与 POST 请求 |
| 201 | Created | (已创建)成功请求并且服务器创建了新的资源 |
| 202 | Accepted | (已接受)已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | (非授权信息)请求成功,但返回的 meta 信息不在原始的服务器,而是一个副本。即服务器已成功处理了请求,但返回的信息可能来自另一来源 |
| 204 | No Content | (无内容)服务器成功处理,但没有返回任何内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | (重置内容)服务器处理成功,但没有返回任何内容,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 300 | Multiple Choices | (多种选择)针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择 |
| 301 | Moved Permanently | (永久移动)请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置 |
| 302 | Found | (临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求 |
| 303 | See Other | (查看其他位置)请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码 |
| 304 | Not Modified | (未修改)自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容 |
| 307 | Temporary Redirect | (临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。与 302 类似,使用 GET 请求重定向 |
| 400 | Bad Request | (错误请求)客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | (未授权)请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | (禁止)服务器理解请求客户端的请求,但是拒绝执行此操作 比如识别到为 csrf 跨域请求而被禁止 |
| 404 | Not Found | (未找到)服务器无法根据客户端的请求找到资源 (网页) 通过此代码,网站设计人员可设置“您所请求的资源无法找到”的个性页面 |
| 405 | Method Not Allowed | (方法禁用)客户端请求中的方法被禁止 |
| 406 | Not Acceptable | (不接受)服务器无法根据客户端的内容特性完成请求 |
| 411 | Length Required | (需要有效长度)服务器无法处理客户端发送的不带 Content-Length 的请求信息 当在 GET 请求中使用 RequestBody 时可能由于无法识别请求体的长度而返回此状态码 |
| 413 | Request Entity Too Large | (请求实体过大)服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个 Retry0-After 的相应信息 |
| 414 | Request-URI Too Large | (请求的 URI 过长)请求的 URI 过长 (URI 通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | (不支持的媒体类型)服务器无法处理请求附带的媒体格式 |
| 500 | Internal Server Error | (服务器内部错误) 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | (尚未实施)服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码 |
| 502 | Bad Gateway | (错误网关) 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | (服务不可用)服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态 |
| 504 | Gateway Time-out | (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
| 505 | HTTP Version not Supported | (HTTP 版本不受支持) 服务器不支持请求的 HTTP 协议的版本,无法完成处理 |
HTTP 消息结构
- HTTP 是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议
- 一个 HTTP “客户端” 是一个应用程序 (Web 浏览器或其他任何客户端,比如 Postman),通过连接到服务器达到向服务器发送一个或多个 HTTP 请求的目的
- 一个 HTTP “服务器” 也是一个应用程序 (通常是一个 Web 服务,如 Apache Web 服务器或 IIS 服务器等),通过接收客户端的请求并向客户端发送 HTTP 响应数据
- HTTP 使用统一资源标识符 (Uniform Resource Identifiers, URI) 来传输数据和建立连接
- 一旦建立连接后,数据消息就通过类似 Internet 邮件所使用的格式和多用途 Internet 邮件扩展 (MIME) 来传送
客户端请求信息
客户端发送一个 HTTP 请求到服务器的请求消息包括以下格式:请求行 (request line)、请求头部 (header)、空行 和 请求数据 四个部分组成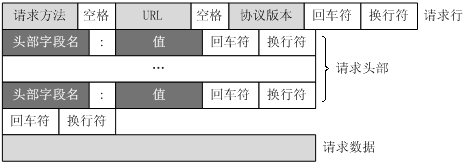
服务器响应消息
HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行、响应正文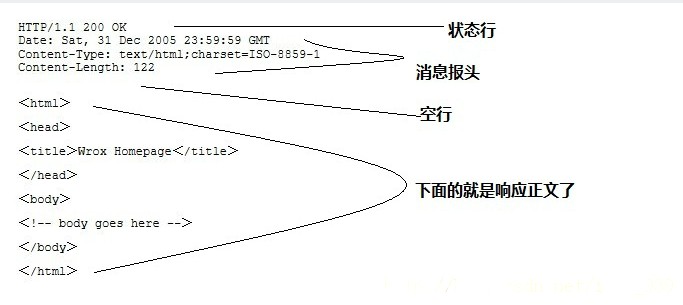
实例
下面实例是一点典型的使用 GET 来传递数据的实例
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务器响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
输出结果:
Hello World! My payload includes a trailing CRLF.
HTTP 响应头信息
HTTP 请求头提供了关于请求、响应或者其他的发送实体的信息
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持那些请求方法(GET、POST 等) |
| Content-Encoding | 文档的编码(Encode)方法,只有在解码之后才可以得到 Content-Type 头指定的内容类型。利用 gzip 压缩文档能够显著地减少 HTML 文档的下载时间。Java 的 GZIPOutputStream 可以很方便地进行 gzip 压缩。但只有 Unix 上的 Netscape 和 Windows 上的 IE4、IE5 才支持它。因此,Servlet 应该通过查看 Accept-Encoding 头 (即 request.getHeader(“Accept-Encoding”)) 检查浏览器是否支持 gzip,为支持 gzip 的浏览器返回经 gzip 压缩的 HTML 页面,为其他浏览器返回普通页面 |
| Content-Length | 表示内容长度,只有当浏览器使用持久 HTTP 连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入 Content-Length 头,最后通过 byteArrayStream.writeTo(response.getOutputStream()) 发送内容 |
| Content-Type | 表示后面的文档属于什么 MIME 类型。Servlet 默认为 text/plain (纯文本),但通常需要显式地指定为 text/html。由于经常要设置 Content-Type,因此 HttpServletResponse 提供了一个专用的方法 setContentType |
| Date | 当前的 GMT 时间。可以用 setDateHeader 来设置这个头以避免转换时间格式的麻烦 |
| Expires | 应该在什么时候认为文档已过期,从而不再缓存该文档 |
| Last-Modified | 文档的最后改动时间,客户可以通过 If-Modified-Since 请求头提供一个日期,该请求将被视为一个条件 GET,只有改动时间迟于指定时间的文档才可能被返回,否则返回一个 304 (Not Modified) 状态。Last-Modified 也可用 setDateHeader 方法来设置 |
| Location | 表示客户应当到哪里去提取文档。Location 通常不是直接设置的,而是通过 HttpServletResponse 的 sendRedirect 方法,该方法同时设置状态代码为 302 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过 setHeader(“Refresh”, “5; URL=http://host/path")让浏览器读取指定的页面注意这种功能通常是通过设置 HTML 页面 HEAD 区的<META HTTP-EQUIV=”Refresh” CONTENT=”5;URL= http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用 CGI 或 Servlet 的 HTML 编写者十分重要。但是,对于 Servlet 来说,直接设置 Refresh 头更加方便注意 Refresh 的意义是”N秒之后刷新本页面或访问指定页面”,而不是”每隔 N 秒刷新本页面或访问指定页面”。因此,连续刷新要求每次都发送一个 Refresh 头,而发送 204 状态代码则可以阻止浏览器继续刷新,不管是使用 Refresh 头还是 <META HTTP-EQUIV=”Refresh” …> 注意 Refresh 头不属于 HTTP 1.1 正式规范的一部分,而是一个扩展,但 Netscape 和 IE 都支持它。 |
| Server | 服务器名字。Servlet 一般不设置这个值,而是由 Web 服务器自己设置 |
| Set-Cookie | 设置和页面关联的 Cookie。Servlet 不应使用 response.setHeader(“Set-Cookie”, …),而是应使用 HttpServletResponse 提供的专用方法 addCookie。参见下文有关 Cookie 设置的讨论 |
| WWW-Authenticate | 客户应该在 Authorization 头中提供什么类型的授权信息?在包含 401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader(“WWW-Authenticate”, “BASIC realm=\”executives\””) 注意 Servlet 一般不进行这方面的处理,而是让 Web 服务器的专门机制来控制受密码保护页面的访问(例如.htaccess) |
文章转载自 菜鸟教程 - HTTP 请求方法
本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。